Deze pagina is een vervolg op onze blogpost over SEO Log File Analyse. Lees die blogpost zeker ook eens. Na een dergelijke SEO analyse wordt je meestal geconfronteerd met URL’s die weinig waarde hebben en die het Crawl budget van je website verzwakken. In dit artikel vertellen we jullie wat een Crawl Budget precies is en hoe je aan crawlbudget optimalisatie kan doen. En dus de SEO van je website kan versterken.
Inhoud:
- Wat is Crawl Budget?
- Waarom is Crawl Budget belangrijk voor SEO?
- Hoe het crawl budget van een site meten?
- Factoren die het crawl budget (negatief) beïnvloeden
- Manieren om het crawl budget te maximaliseren
Wat is Crawl Budget?
Onder crawl budget verstaan we het aantal URLs dat Googlebot kan en wil crawlen op een website binnen een bepaalde tijdsspanne. We willen immers allemaal dat Google en andere zoekmachines zo snel mogelijk site-veranderingen ontdekken en belangrijke content zo snel mogelijk in de zoekresultaten opnemen.
Heeft een website geen aandacht voor haar crawl budget, dan kan dit leiden tot een daling van de dagelijkse crawl allocatie, indexatie ratio en ranking zoekwoorden. Kortom tot een daling van je site-SEO.
Waarom is Crawl Budget belangrijk voor SEO?
Google zal het internet niet onbeperkt blijven crawlen om op zoek te gaan naar nieuwe content. Immers, zelfs Google kent een eindig budget. Het is een machine die al de gevonden data van het world wide web moet opslaan in datacenters. En die kosten geld. Om kosten te besparen, wil het maximaal enkel kwaliteitsvolle webpagina’s crawlen. Daarvoor gaat het opzoek naar signalen op je website die daarop duiden.
Houd rekening met:
- indien het aantal URLs van een website haar crawlbudget overschrijdt, dan zullen er pagina’s zijn niet zullen worden gecrawld en geïndexeerd;
- als je website teveel niet-zinvolle URL’s kent, kan het je crawlbudget zelfs verlagen;
- en indien een URL niet is gecrawld of geïndexeerd, dan kan die ook niet ranken in de zoekresultaten;
- anders gezegd: je wil dus vooral vermijden dat Google je crawlbudget verspilt aan waardeloze URLs.
Dit gezegd zijnde …
De overgrote meerderheid van (kleinere) websites hoeft zich echter geen zorgen te maken over haar crawl budget. Google is meestal goed in staat in het vinden en indexeren van URLs.
In volgende gevallen speelt crawlbudget evenwel WEL een grote rol:
- Grote websites met erg veel URLs (bijvoorbeeld sites van uitgevers met duizenden pagina’s): hier kan Google moeite hebben om ze allemaal te ontdekken;
- Voor e-commerce websites die automatisch pagina’s genereren op basis van URL-parameters;
- Je hebt net honderden nieuwe pagina’s toegevoegd aan je website; in dat geval wil je voldoende crawlbudget hebben om ze allemaal snel te indexeren;
- Websites met erg veel 30X-redirects; deze eten je crawl budget op.
Hoe het crawl budget van een site meten?
Via Google Search Console krijg je een idee van het crawlbudget van jouw website. Ga naar je GSC-Account > Instellingen > Crawlstatistieken > Rapport openen. Je ziet er het aantal crawlverzoeken per dag. Voor onderstaande site schommelt het crawlbudget rond 39K per dag (3,53 miljoen verzoeken over de laatste 90 dagen).

Een andere wijze is via log file analyse. Lees er alles over in onze blogpost SEO Log file analyse.
Factoren die het crawl budget (negatief) beïnvloeden
Het optimaliseren van het crawlbudget komt er vooral op aan geen crawlbudget te verspillen. Het aanpakken van deze verspillers is de manier om ermee op te gaan, zoals:
- facetnavigatie bij e-commerce-sites: foutieve implementatie kan een enorme hoeveelheid aan indexeerbare URL’s veroorzaken;
- duplicate content;
- trage laadsnelheid website;
- content van lage kwaliteit & spam.
Manieren om het crawl budget te maximaliseren
1. Laadsnelheid
Misschien wel het nummer 1 advies voor crawl budget optimalisatie. Immers, hoe sneller een website laadt, hoe meer URLs Google kan crawlen in dezelfde tijdsspanne. En dus hoe groter je crawl budget. Lees daarom zeker dit artikel over Core Web Vitals & website snelheid optimalisatie.
2. Verminder error pages
Een andere manier om het crawl budget te maximaliseren is het aantal error pages verminder. Zorg ervoor dat de pagina’s die worden gecrawld ofwel statuscode 200 of 301 hebben. Alle andere statuscodes zijn te vermijden. Bekijk hiervoor de logs files van je site. De beste manier om dat te doen is door alle URL’s te verzamelen die geen 200 of 301 zijn. Bekijk hoe vaak deze voorkomen en los op. Een goede tool om deze te ontdekken is bijvoorbeeld Screaming Frog.
3. Geen redirect chains
Redirect chains verminderen je crawlbudget en zijn te vermijden. 301 redirects met 1 of 2 tussenstations vormen geen probleem. Zodra het er meer dan 4 zijn echter wel. De kans dat Googlebot al deze redirects volgt, is erg klein. Je kan ze opsporen en oplossen via bijvoorbeeld Screaming Frog en je logfiles.
4. Meer backlinks
Nog een erg belangrijke crawl budget optimalisatie tip: backlinks. URLs van je site die backlinks van andere websites hebben, vertellen aan Google welke content echt belangrijk is. Externe links bekomen is gemakkelijker geschreven dan gedaan. Meer externe back links krijgen is niet alleen een kwestie van fantastische content. Het is vooral anderen laten weten dat je ijzersterke zinvolle content hebt. Veel meer info rond linkbuilding vind je hier:
5. URLs met parameters blokkeren
URL parameters zijn nodig voor onder meer :
- paginatie (vb: /nieuws/alle-artikelen?page=55)
- filtering (vb: /tennisschoenen?type=gravel&prijs_tot=50&materiaal=textiel)
- site search (vb: /search?q=tennisrackets)
- tracking (vb: actiepagina?UTM_campaign=kerstmis22&utm_medium=email&utm_content=123456).
Het gebruik van dergelijke URL parameters kan echter tot een enorme hoeveel aan pagina’s met gelijkaardige content leiden. Als crawlers veel URL’s ontdekken die allemaal versies zijn van dezelfde pagina, dan voorzien mogelijks niet genoeg crawl budget aan je echt waardevolle pagina’s.
6. Blokkeer delen van je website
Verspil dus geen crawl budget aan URLs die nauwelijks zinvolle content of toegevoegde waarde bevatten. Deze kan je op een aantal manieren afschermen van crawlers.
Robots.txt

Met het robots.text-bestandje kun je bepaalde delen van een website afschermen voor zoekrobots. Het is dus eigenlijk een trucje waarbij we bepaalde delen van een website niet toegankelijk maken voor de zoekmachine-crawlers. Het is één van de oudste manieren die nu nog gebruikt worden. Wanneer we praten over duplicate content is het niet aangeraden om robots.txt te gebruiken. Want wanneer er op versie 2 eventuele ranking-signalen zouden binnenkomen, worden deze niet doorgestuurd naar versie 1. Terwijl dit met een rel=canonical, 301-redirect en URL-parameters wel al het geval is. Dezelfde redenering kunnen we ook volgen voor de meta-robots opdracht <follow,noindex>
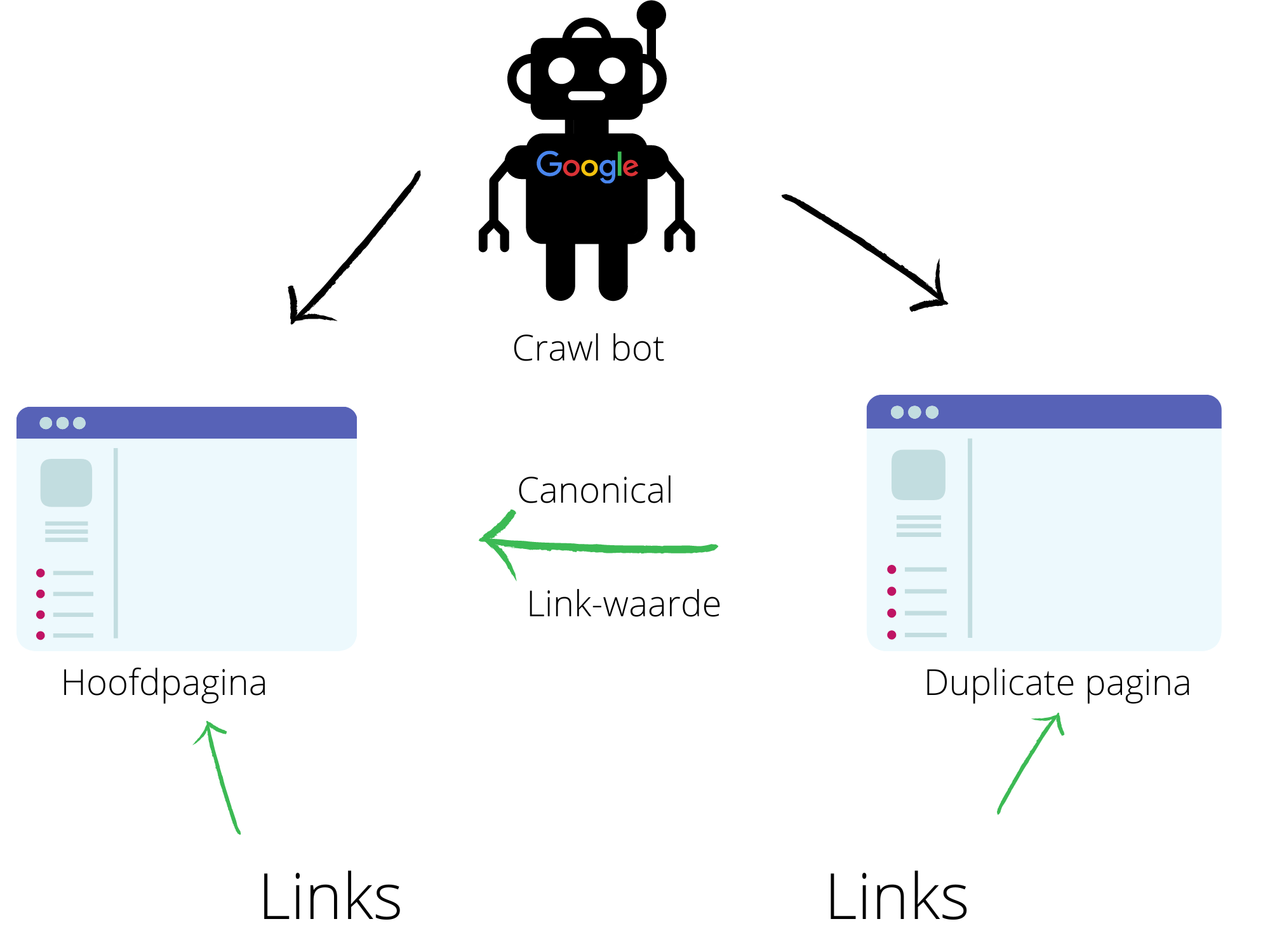
Canonical tag
Een andere manier om met URL’s van een lage waarde om te gaan is gebruik te maken van een canonical tag. We gaan een canonical-tag toevoegen wanneer de content van twee of meerdere web-url’s zeer gelijkaardig of exacte kopieën zijn. Deze tag kan ook gebruikt worden wanneer we 2 webpagina’s hebben waarvan de content niet identiek is, maar deze wel over hetzelfde onderwerp gaan.
Het mooie van canonical-tags is ook dat ze linkwaarde doorgeven aan de hoofd-url. Schematisch kunnen we dit als volgt voorstellen:
301-redirect

Wanneer we een 301-redirect instellen, krijgen we het volgende: zodra bezoeker op pagina X, wordt deze automatisch omgeleid naar pagina Y. Het verschil met de canonical tag is dat de bezoeker op de oorspronkelijke pagina gehouden wordt. Door dit te doen, zeggen we eigenlijk tegen Google van versie X was een vergissing. Je mag ze naar versie Y sturen want dit is de enige juist.
Samenvatting
Collega SEOer Ryan Stewart legt in onderstaande presentatie goed het belang van Crawl Budget nog eens uit.
Meer weten over SEO?