Benieuwd of je website een kwalitatieve SEO heeft? We contacteren je zo snel mogelijk.

SEO Website indexatie
Website indexatie één van de taken van een zoekmachine. Website indexatie is het proces dat komt na Crawling en rendering, maar voor Ranking.
Je kan maar gevonden worden op het internet voor zoekopdrachten, als de corresponderende webpagina’s ervan ook geïndexeerd zijn door de zoekmachines. Is dat niet het geval, dan kunnen die geen organisch SEO zoekverkeer aantrekken. Daarom is het erg interessant te weten welke pagina’s niet worden geïndexeerd door Google en co, zodat je dit probleem kunt oplossen en je SEO-posities weer een boost geven.
De hoofdfuncties van een zoekmachine
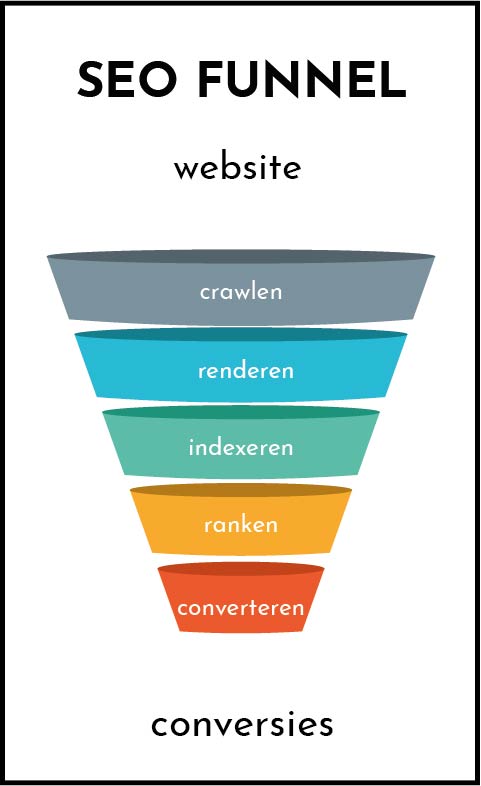
Zoekmachines kennen 4 grote taken:
- Crawlen
- Renderen
- Indexeren
- Ranken
In mensentaal betekent dit eigenlijk dat zoekmachines werken in 4 fases:
- Het opsporen van online web-content op het internet (= crawling ofwel fase 1)
- Achterhalen hoe URLs eruit zien (= rendering ofwel fase 2)
- Het catalogiseren van die gevonden web-info (=indexing ofwel fase 3)
- Een zo accuraat antwoord bieden op zoekopdrachten in de zoekresultaten (=ranking ofwel fase 4)
Fase 1: Crawling

- Het crawlproces van search engines is een beetje te vergelijken met een metro-netwerk.
- Beschouw elke metrohalte als een unieke webpagina, video of afbeelding.
- De weg naar elke halte mag dan zien als als een link.
- Om de hele metroplattegrond (lees het internet) in kaart te brengen en alle stopplaatsen (lees webpagina’s) te ontdekken, gebruikt de metro (lees de zoekmachine) de meest geschikte weg (lees links).
- Hyperlinks zijn dus hét bindmiddel op het world wide web en laten zoekmachines toe de vele miljarden webcontent te bereiken en te ontdekken.
- Om die content te ontdekken, gebruikt Google spiders of Google-bots. Deze bots bezoeken enkel gekende, te vertrouwen websites.
- Telkens als zo’n bot een hyperlink op een URL aantreffen, zullen ze die eveneens crawlen.
- De spiders gaan dus van link naar link naar link … en sturen de gevonden informatie terug naar hun datacenters.
- Is een webpagina niet verbonden met andere webcontent, dan kan het niet gecrawld of geïndexeerd worden. Deze “wezen” of “orphan pages” zullen dus niet in de search results verschijnen.
- Verder is het goed om weten dat elke website een zogenaamd crawl budget heeft. Google zal zeker erg grote websites met vele honderd duizenden URL’s, niet volledig crawlen. Het is dan ook belangrijk dat die grote sites hun voornaamste URL’s laten crawlen.
- Je kan de crawlbaarheid of crawlabilty van een website verhogen door:
- een duidelijke site structuur;
- heldere interne linking;
- het vermijden van kapotte hyperlinks;
- geen niet-crawlbare content te hebben.
Fase 2: Rendering
- Rendering is het proces waarbij Googlebot de gevonden pagina’s ophaalt, de code uitleest en de inhoud beoordeelt. Alle informatie die Google verzamelt tijdens het renderingsproces wordt vervolgens gebruikt om de kwaliteit en waarde van de content te evalueren.
- Eenvoudig gezegd is rendering het gebruiken van een browser om de JavaScript uit te voeren en te zien hoe de pagina eruit zou zien voor een gebruiker. Het verschil is dat Google dit doet zonder de pagina echt te openen, maar door de tool “Puppeteer” op een webserver te laten draaien.
- Nadat een crawler een pagina heeft gevonden, rendert de zoekmachine deze net zoals een browser dat zou doen. Daarbij analyseert de zoekmachine de inhoud van de URL.
- Al die informatie wordt opgeslagen in de index. Het feit dat een website kan worden gecrawld door een zoekmachine betekent echter niet automatisch dat die ook wordt opgeslagen in hun index.
- Bijgevolg kent een webpagina dus 2 statussen
- de oorspronkelijke html, die je via de broncode kunt bekijken.
- de gerenderde html, ook wel DOM of Document Object Model genoemd. Het vertegenwoordigt de oorspronkelijke HTML + eventuele wijzigingen door JavaScript waarop html beroep deed. Te bekijken via de Inspect tool.
- Belangrijk: Google kan niet indexeren wat het niet kan renderen.
Fase 3: Indexering
De Google-bot crawlt dus het internet en plaats nieuwe en bijgewerkte webpagina’s in enorme databases. De index is waar je ontdekte pagina’s worden opgeslagen. Deze vormen op hun beurt de basis voor website indexatie. Dit zoekproces start met een lijst van URL’s van eerdere zoekprocessen en wordt aangevuld met de sitemap-data. Google-bot doorzoekt al deze sites en de gevonden hyperlinks worden opgenomen in de lijst van te crawlen pagina’s. Nieuwe websites & bestaande bijgewerkte pagina’s & broken backlinks worden alzo geanalyseerd en gebezigd om de index te actualiseren.
Fase 3: Ranking
Alle gecrawlde pagina’s worden verwerkt in een enorme index, die alle gevonden woorden en meta-informatie bevat, samen met de locatie van elke pagina. Zodra een surfer een zoekwoord intypt in een browser, wordt die mega-index doorzocht op de meest relevante resultaten, die dan in een fractie van een seconde in de zoekresultaten weergegeven worden. Samengevat, indien een URL is geïndexeerd, dan is deze vindbaar, om weergegeven te kunnen worden in de zoekresultaten voor een bepaalde zoekopdracht.
Het belang van een Technische SEO audit
- Zoals hierboven beschreven werken zoekmachines in 3 stappen: 1) crawling, 2) website indexatie en 3) ranking.
- Indien echter een website verhindert dat search engines haar webpagina’s kan crawlen of indexeren, dan kan die site niet ranken in de zoekresultaten.
- Dit blokkeren van crawlers gebeurt vaak onbewust.
- Indien een site dus crawlers verhindert haar website te crawlen, kan deze niet geïndexeerd worden, en bijgevolg ook niet gevonden worden in de zoekresultaten.
- Een andere mogelijkheid is dat een website wel kan worden gecrawld en geïndexeerd, maar dat de content niet volledig begrepen wordt door de zoekmachines. Gevolg: lage rankings en erg weinig organisch zoekverkeer.
- Daarom is het essentieel op regelmatige basis een SEO audit uit te voeren voor SEO succes.
- Zo ontdek je of bepaalde webpagina’s niet geïndexeerd worden omwille van een crawl-probleem. Of dat je niet ranked omdat er een indexeringsprobleem is.
- Als een technisch SEO audit ontdekt waar SEO probleem zich precies situeert (bij de crawling, indexering of ranking), helpt dat het issue veel gerichter op te lossen.

Website indexatie controle tools
Indexatie-ratio
- Een URL kan dus maar voorkomen in de zoekresultaten indien het geïndexeerd is de zoekmachines.
- Daarom is het erg waardevol te weten hoeveel URL’s van een website door Google zijn opgenomen in haar index.
- En meer specifiek: hoeveel webpagina’s staan er op een site en hoeveel van de pagina’s zitten in de index van een search engine ?
- Deze verhouding wordt indexatie-ratio genoemd
- dus indexatie-ratio = aantal geïndexeerde URL’s / totaal aantal URL’s
- Zie onderstaande figuur: je hebt dan 3 mogelijke scenario’s voor een website:
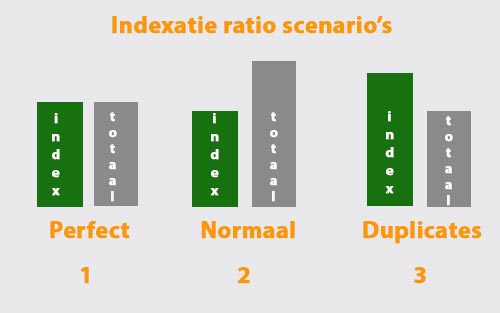
- In een perfecte situatie zijn alle URL’s van een website ook geïndexeerd door Google (zie scenario 1)
- Het meest voorkomende scenario (zie 2) is waarbij er minder webpagina’s in de index zetten dan het totale aantal van een site. Goed geoptimaliseerde SEO sites doen dit bewust via de robots.txt file.
- Ofwel is er scenario 3 waarbij er méér pagina’s in de index zitten dan het totaal. Meestal is de oorzaak hier duplicate content.
Om nu te weten hoeveel URL’s van een website in de index van Google zitten, kan je volgende zaken doen:
Site:
Een mogelijkheid om te controleren hoeveel pagina’s van een website zijn geïndexeerd, is het commando site: met de naam van de website er direct tegenaan (zonder de https://www ) in de zoekbalk van Google te typen. Bijvoorbeeld site:onlinemarketingmonkey.be . Deze manier van website indexatie is niet altijd even betrouwbaar omdat de resultaten al eens durven te wijzigen.

Eerst is het resultaat 310 op google.be. Als je naar het einde toe door scrollt, zijn het er plots maar 298. Je wordt met dezelfde veranderende cijfers ook geconfronteerd in Bing (geeft als 548 resultaten) en Yahoo (eveneens 548 pagina’s in de index). Samen met de Google score krijg je zo wel een beeld van de orde van grootte van het aantal geïndexeerde pagina’s, die waarschijnlijk voor dit voorbeeld momenteel rond de 300 zal liggen.
Search Console
Als we nu in Google Search Console gaan kijken, zien we bij Dekking > “Ingediend en geïndexeerd” de score 284 staan. Er van uitgaande dat site:-opdracht niet helemaal betrouwbaar lijkt, is het wel een goed teken dat deze resultaten ongeveer overeenkomen.

Sitemap
- Blijven we in Search Console en kijken we bij “sitemaps”, dan is het resultaat 298 pagina’s in de index.
- Dus een klein verschil met de 284 hierboven.
- Betekent dit nu dat de sitemap-data in GSC niet accuraat is? We geven hieronder de verklaring.
- Verder informatie:
- het versturen van de sitemap via Google Search Console helpt de zoekmachine om de website structuur beter te begrijpen.
- Soms ontdekt het zelfs URL’s die tijdens het normale crawlproces niet zijn opgepikt.
- Echter, een sitemap garandeert niet dat zoekmachines alle opgegeven webpagina’s zal crawlen of zal indexeren.
- Zie het op de eerste plaats als een soort advies-tool.
- Sitemaps vertellen aan search engines welke pagina’s ze moeten crawlen, zonder garantie dat die ook daadwerkelijk geïndexeerd gaan worden.
Analytics
- Nog een mogelijkheid: kijk in Google Analytics ( via Rapporten > Acquisitie / Search Console / Bestemmingspagina’s) welke landingspages SEO verkeer ontvangen, zie afbeelding hieronder.
- Dit getal (340) vertelt hoeveel unieke pagina’s minstens 1 bezoek van de google-crawler hebben ontvangen.
- Indien je dit cijfer elke maand checkt, kan het je meer inzicht geven of je URL’s meer organische bezoekers aantrekken of niet.
- Opgelet, net als bij de sitemap, zegt dit cijfer niet het exacte aantal geïndexeerde webpagina’s, maar geeft dus wel het aantal URL’s weer die minimaal 1 bezoek van een zoekmachine gekregen hebben, wat ons inziens het meest interessant is.
- Waarom? Wel, indexcijfers alleen zijn eigenlijk zinloos. Immers, het betekent dat die pages in de index zijn geraakt. Mooi, maar dat wil nog niet zeggen dat die pages ook webverkeer ontvangen.
- Anders gesteld: SEO’ers & webmasters moeten niet bezorgd zijn of URL’s in de index staan, maar wel of die ook echt bezoekers aantrekken. Het cijfer vertelt of engines je URL’s ook echt crawlen, indexeren én vermelden in de zoekresultaten.
![]()
Niet geïndexeerde URL’s opsporen
Hoe nu geïndexeerde webpages opzoeken ? Wel, dat is eigenlijk moeilijker dan gedacht. Search Console en site:-opdracht geven daarover namelijk geen info.
- Een oplossing is afzonderlijk 1 voor 1 elk webpagina’s te checken of ze in de index staan via het site:commando. Maar dit is veel te tijdrovend, zeker als je duizenden pagina’s dient te controleren

- Een andere optie is de opdracht ‘inurl:’ of ‘info’ te hanteren, maar dit is ook handmatig uit te voeren.
- Het snelst gaat met een combinatie van (betalende) SEO tools als Screaming Frog, URL Profiler en Excel:
- met screaming-frog scan je eerst alle URL’s van je website;
- vervolgens kan je via URLProfiler met hun handige functie “indexed in Google ” automatisch per pagina van je sitemap checken of die geïndexeerd is;
- vervolgens kan je in Excel met de functie =ALS.FOUT(VERT.ZOEKEN(A2;F:F;1;0);”Niet geindexeerd”) snel die pagina’s opzoeken die niet in de google index staan;
- op deze manier krijg je op een semi automatische wijze een beeld van de website indexatie; voor ons voorbeeld zijn dat er 9, waarvan het perfect logisch oogt dat ze niet opgenomen zijn (zie volgend punt).
Echter, in plaats van alle individuele non-indexed pages te overlopen, is het beter ervoor te zorgen dat elke pagina high-quality content heeft en dat de site veel backlinks kent. Weet dat Google geen enkele waarde aan de niet-geïndexeerde pagina’s schenkt, de welke dus niet kunnen ranken noch online bezoekers kunnen aantrekken
Waarom zijn bepaalde webpagina’s niet geïndexeerd ?
Zoekmachines ontdekken webpagina’s via links van andere sites en via de ingediende XML-sitemaps in de Search Console. De engines crawlen de pagina’s om te bepalen of de content voldoende waardevol is voor surfers en hun respectievelijke zoekopdrachten. Ze komen in aanmerking voor website indexatie indien indien voldoende relevant.
Redenen waarom sommige webpages niet geïndexeerd zijn + uitleg waarom de resultaten van de sitemap verschillen van de google indexeringsstatus:
Tijdgebonden oorzaken
- soms staan de pagina’s wel in de search results, maar bijvoorbeeld pas op positie 725, waardoor het lijkt alsof ze geen index-status hebben;
- bij nieuwe websites duurt het een tijdje vooraleer de Googlebot deze heeft opgemerkt. De goede oplossing hiervoor is een backlink van een andere, al bestaande geïndexeerde website te zetten naar de jouwe waardoor de bots bij het crawlen ook de jouwe ontdekken;
- pas een nieuwe sitemap ingediend of heel wat nieuwe URL’s ? Wees geduldig, want het duurt een tijdje vooraleer alle pagina’s geïndexeerd zijn.
Technische redenen
- houd er ook rekening mee dat de zoekmachines soms ook gewoon niet aan sommige pagina’s kunnen omdat ze gewoon te “diep” weggestopt zitten in een site. Kan opgelost worden door internal linking, bijvoorbeeld vanaf de homepage of via pagina’s er juist onder en door nieuwe pagina’s zo dicht als mogelijk bij de domeinnaam zelf te houden;
- al vaker ter sprake in onze blog-artikelen: omdat je per ongeluk de bots verbiedt je pagina’s te crawlen met je robots.txt file;
- door duplicate content. Is het gemakkelijkst uit te leggen voor een webwinkel. Heb je bijvoorbeeld 1.00 artikelen, dan heb je hiervoor normaliter ook 1.00 individuele webpagina’s. Als deze productpagina’s bijvoorbeeld alleen maar van elkaar verschillen in bijvoorbeeld de kleur of een ander klein technisch detail, dan kunnen de search engines die pagina’s wel eens als hetzelfde beschouwen en er slechts enkele van indexeren. Zorg dus steeds voor veel unieke content op elke webpagina !
- een pagina die toegankelijk is met en zonder “www” telt voor de sitemap als 1 pagina, voor de indexstatus echter als 2;
- hetzelfde geldt voor URLs met resp. http en https;
- oude content die soft 404’s hebben, in plaats van 401 of 301.
Andere oorzaken
- verder hanteert Google de sitemap als een soort website-plattegrond om URL’s te ontdekken, maar deze bepaalt echter niet wat daarvan nu wel of niet geïndexeerd dient te worden. De map kan dus URL’s bevatten die enkel voorkomen in haar bestand, maar die een surfer niet zal aantreffen in de search results omdat de engines ze niet voldoende kwalitatief vindt voor relevant zoekopdrachten
- verder vermoeden we dat google niet alle pagina’s uit de sitemap indexeert omdat ze ervan uitgaat dat de geïndexeerde URL’s als voldoende representatief beschouwt voor het totaal aantal aangeleverd, met als redenering dat met nog meer geïndexeerde URL’s de search results niet beter zullen worden. Om het met Google’s eigen woorden te zeggen:
We indexeren miljarden webpagina’s en proberen dit aantal voortdurend te verhogen. We kunnen echter niet garanderen dat we alle pagina’s van een site crawlen. Google crawlt niet alle pagina’s op internet en we indexeren niet alle pagina’s die we crawlen. Het is volstrekt normaal dat niet alle pagina’s op een site worden geïndexeerd.
Samenvattend
Het niet-indexeren van webpagina’s door zoekmachines is nadelig voor je vindbaarheid en je SEO posities. Het kan diverse oorzaken hebben. Verbeter je website indexatie door bovenstaande adviezen toe te passen. Het verband tussen en SEO en crawling, indexering en ranking wordt visueel uitgelegd in onderstaande infographic.




Ik kwam voor de eerste keer op deze website en vond de content echt bruikbaar. Het heeft me echt geholpen.