
Llms.txt is een nieuw, LLM-vriendelijk bestand dat AI-tools zoals Gemini, ChatGPT, en Perplexity helpen een website beter te begrijpen. Je mag het zien als een soort elevatorpitch waarin een website aan een LLM uitlegt wat het eigenlijk doet.
Inhoudsopgave
Situering
Large language models (LLM’s) zoals Gemini en ChatGPT zijn getraind om een breed palet aan onderwerpen te begrijpen. Maar vraag ze een specifieke website te interpreteren, dan lopen ze tegen enkele problemen aan:
- De html van veel websites is vaak minder goed gestructureerd: navigatiebalken, cookie-banners, pop-ups en allerlei scripts maken een URL onoverzichtelijk.
- Verder zijn de meeste websites te groot om volledig in 1 maal gecrawld te worden
- De site info is meestal verspreid over meerdere pagina’s
- Bovendien functioneren LLM’s niet zoals zoekmachines:
- search engines crawlen en indexeren je hele site
- AI-tools scannen alleen kleine gedeeltes in realtime wanneer ze reageren op een bepaalde prompt
- Daardoor missen ze vaak belangrijke informatie
Gevolg: het model mist context en ziet verkeerde signalen. Dit leidt tot onvolledige en verouderde antwoorden.
Traditionele SEO helpt je website om gevonden te worden. Maar dat garandeert niet dat AI-tools begrijpen wat een menselijke gebruiker zou begrijpen. Daarom dat er een nieuwe standaard wordt voorgesteld om dit euvel te verhelpen: de llms.txt.
Wat is llms.txt?
llms.txt, de afkorting voor large language model sitemap, is de voorgestelde standaard die LLM’s zou moeten helpen om snel de structuur, het doel en de inhoud van een website te begrijpen. En dit zonder afhankelijk te zijn van html en andere SEO-metadata.
Het is een lichtgewicht tekstbestand dat Chatgpt en andere LLMs vertelt waar ze relevante informatie over een website kunnen vinden:
- het biedt een korte samenvatting van je site
- het linkt naar schone, leesbare Markdown-versies van relevante URLs
- het bestand helpt AI-tools dus te bepalen wat belangrijk is, zonder de ganse html te moeten doorploegen
Bestaat dit niet al met Robots.txt + Sitemap.xml ?
LLMS.txt doet inderdaad erg denken aan de robots.txt en de sitemap.xml, maar is niet hetzelfde:
- Een robots.txt bestand is zoals llms.tx een eenvoudig tekstbestand, maar vertelt zoekmachines welke delen van een website ze wel en niet mogen bezoeken.
- De xml sitemap is dan weer een lijst met alle belangrijke pagina’s op een website die je graag geïndexeerd wilt hebben.
- De llms.txt heeft momenteel geen impact heeft op je zichtbaarheid in Search; dat geldt wel voor robots.txt en de sitemaps.
Deze tabel geeft het onderscheid tussen llms.txt, robots.txt en xml-sitemap:
| Kenmerk | robots.txt | sitemap.xml | llms.txt |
| Functie | Informeert crawlers welke delen van een website ze wel of niet mogen crawlen. | Helpt zoekmachines sneller belangrijke pagina’s van een website te ontdekken. | Informeert LLMs in grote lijnen waarover een website gaat |
| Toepassing | *Beheren van crawlgedrag: Voorkomen van indexatie van irrelevante of gevoelige pagina’s. * Crawl budget optimalisatie: Zorgen dat crawl-resources worden besteed aan belangrijke content. * Voorkomen van serveroverbelasting. |
* Verbeteren van indexatie: Er voor zorgen dat zoekmachines alle relevante pagina’s vinden, vooral bij grote/complexe sites. * Informatie verschaffen: Extra metadata over pagina’s (laatste wijziging, etc.). * Snellere ontdekking van nieuwe content. |
Focus op runtime gebruik (bij het beantwoorden van vragen), niet op training. |
| Status | Standaard protocol (Robots Exclusion Protocol), breed ondersteund door zoekmachines. | Geaccepteerde standaard voor zoekmachines om websites beter te begrijpen. | Hypothetisch concept. Bestaat momenteel niet als een officiële of breed geïmplementeerde standaard. |
Wordt Llms.txt reeds breed ondersteund ?
- Neen. Nog geen enkele grote LLM-aanbieder ondersteunt momenteel llms.txt. Niet OpenAI. Niet Google. Dus zonder adoptie door grote spelers heeft het momenteel nog weinig waarde.
- Het is nog een relatief jong idee & gelanceerd in september 2024
- Maw: llms.txt is nu nog een speculatief idee zonder officiële ondersteuning.
Er bestaat ondertussen wel een llms-community directory.llmstxt.cloud. Het is een groeinde directory met websites die reeds een llms.txt-bestand hebben geïmplementeerd. Het overzicht is bedoeld om te laten zien welke organisaties de standaard omarmen en ontwikkelaars te laten zien hoe anderen hun bestanden structureren.
Voorbeeld van een llms.txt-bestand
Hier een voorbeeld van de webisite Coolify hoe zo’n llms.txt-bestand eruit kan zien.
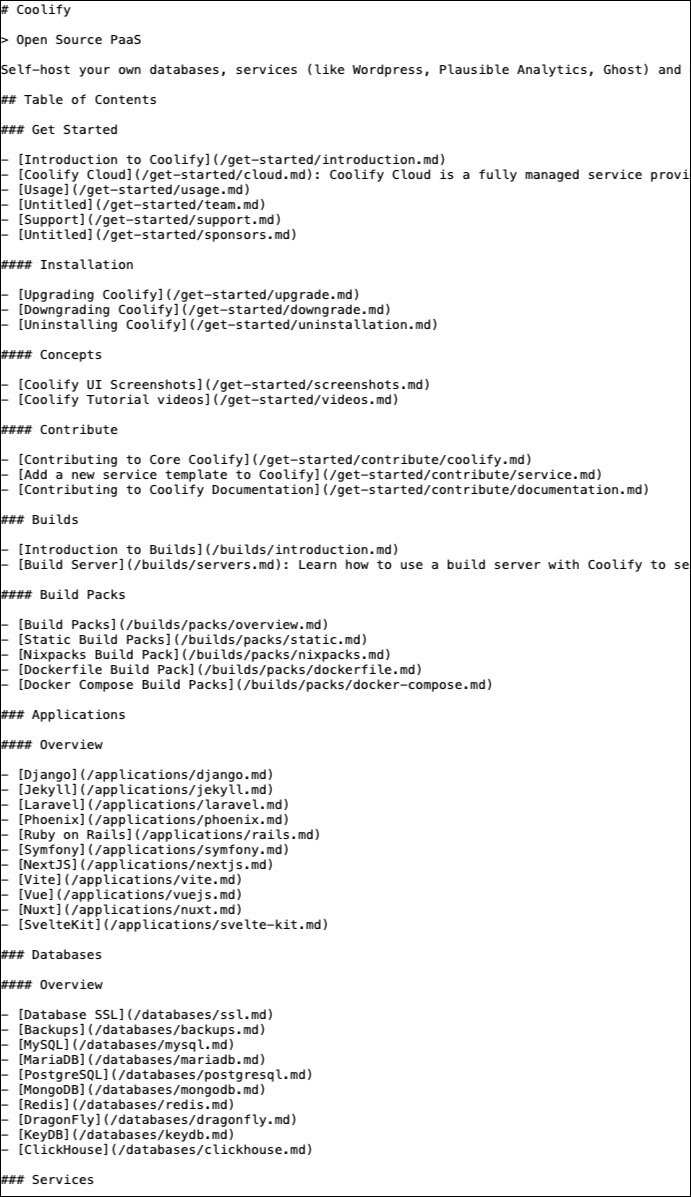
Zelf een llms.txt maken?
Niet zo moeilijk. Volg deze stappen
- Maak een .txt bestand geschreven in .md of .html of .php of met gewone URL’s, zolang de content maar gestructureerd en toegankelijk is
- Gebruik H1/H2/H3-koppen (via de zgn # ) om bronnen te groeperen per type
- Link naar goed leesbare content
- Houd het bestand up-to-date
- Host het op je rootdomein: https://www.website.be/llms.txt
Er zijn gratis LLMS.txt generators beschikbaar om je hierbij te helpen.
Dus… is llms.txt al echt nuttig?
Nee, nog niet per direct.
Belangrijkste argument: een llms.txt maken betekent niet dat crawlers het volgen. Vooralsnog behandelen de meeste LLM-aanbieders het als een interessant idee, maar niet als een echte standaard. Er is geen bewijs dat llms.txt zorgt voor betere AI-opnames, meer verkeer of accuratere modellen.
Maar het is wel eenvoudig in te stellen. En wie weet levert het later wél iets op als het ooit breed geadopteerd wordt. Waarschijnlijk wint het aan populariteit omdat we gewoon allemaal invloed willen uitoefenen op LLM-zichtbaarheid.
Mijn advies : het is een toevoeging met weinig moeite en geen risico. Je bereidt je website voor op een toekomst van nog meer AI Search waarin gestructureerde toegang tot LLM’s mogelijk wel genormaliseerd wordt.
En hé, zo zijn mobile first, sitemap.xml en https ooit ook begonnen als optioneel, om dan later uit te groeien tot een vaste standaarden. We hebben de onze llms ondertussen al gemaakt 🙂
Meer bijleren over AI en Search ? Schrijf je dan in voor onze nieuwsbrief!
Gerelateerde berichten
![Checklist: Zo optimaliseer je voor LLMs en AI-zoekmachines]()
Checklist: Zo optimaliseer je voor LLMs en AI-zoekmachines
![Onderzoek- De evolutie van Google AI Overviews in België nieuwe mogelijkheden voor online succes]()
Onderzoek november 2025 - De evolutie van Google AI Overviews in België: nieuwe mogelijkheden voor o...
![Hoe te verschijnen in AI antwoorden: wat we de afgelopen weken geleerd hebben]()
Hoe te verschijnen in AI antwoorden: wat we de afgelopen weken geleerd hebben
![Log file analyse]()
SEO Log file analyse: waarom het cruciaal is in het tijdperk van AI-zoekmachines


