De XML sitemap van een website helpt Google bij het crawlen en indexeren van een website. In deze blogpost helpen we graag om jouw website verder te optimaliseren voor SEO. Deze zaken komen aan bod:
- Wat is een XML Sitemap ?
- Hoe ziet een XML bestand eruit?
- Is het belangrijk voor SEO?
- Adviezen voor een goede XML sitemap
- Ook goed om weten
- Interessante vragen
Wat is een XML sitemap?
Een XML sitemap is een file waarin alle belangrijke URLs van een website zijn opgesomd. Het is bedoeld om zoekmachines een overzicht te geven van alle webadressen die op een site staan. Zo kunnen ze die gemakkelijker vinden en indexeren. Een goede XML sitemap helpt dus een website om sneller gevonden en geïndexeerd te worden door Google.
Hoe ziet een XML sitemap eruit?
De XML sitemap bevat de volgende onderdelen:
- Een XML-verklaring om crawlers duidelijk te maken welk type bestand & protocol ze aan het lezen zijn;
- De URL: vermeldt het webadres van de verschillende (hoofd)-pagina’s;
- Last modified: een datum die vermeldt wanneer een URL voor het laatst is gewijzigd;
- Sommige sitemaps vermelden eveneens nog <priority>en <changefreq>: dat mag, maar hebben sinds enige tijd geen enkel effect meer.
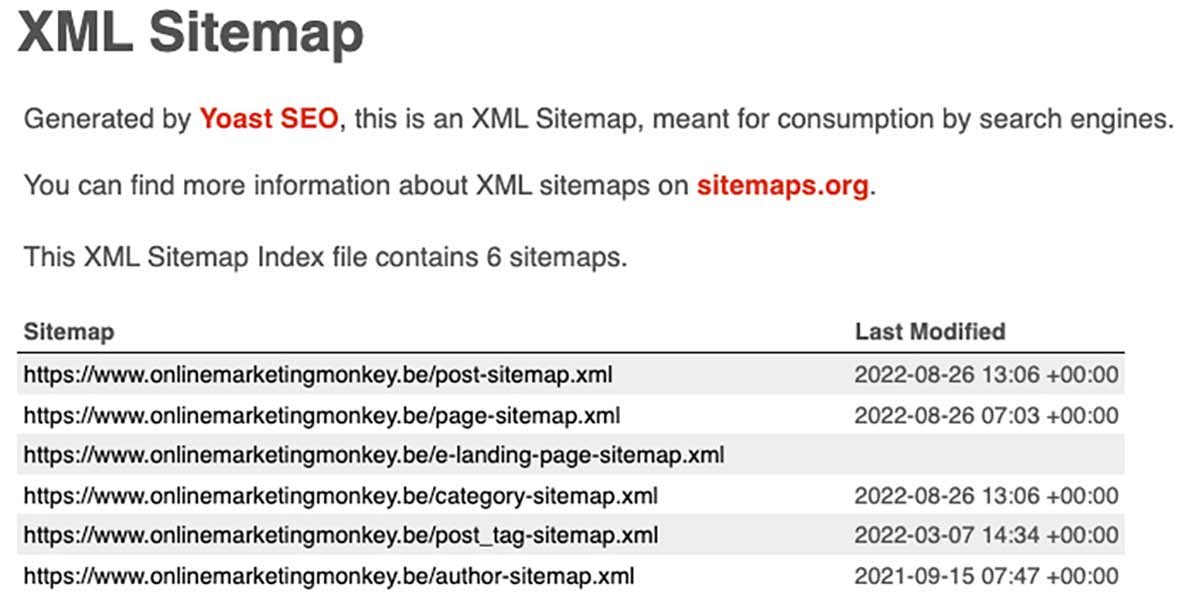
Hieronder zie je een voorbeeld van de sitemap van Online Marketing Monkey. Ze is onderverdeeld in een aantal sub-sitemaps: 1 met alle berichten, 1 met met pagina’s, 1 met alle categorieën enz. Als je op 1 van deze subsitemaps doorklikt, krijg je de URLs te zien die eronder vallen.
Is een XML sitemap belangrijk voor SEO?
Zeker in de beginjaren van SEO waren XML-sitemaps een snelle manier om de search engines nieuwe URLs te laten crawlen. Tegenwoordig is het SEO belang minder geworden.
In tegenstelling tot wat men vaak denkt, zijn XML-sitemaps echter geen SEO ranking factor. Maar ze hebben nog steeds hun nut: je site is gemakkelijk te crawlen, waardoor Google beter interne links kan ontdekken, wat dan weer goed is voor je SEO.
Adviezen voor een goede XML sitemap
- Voeg alleen URL’s toe die je echt geïndexeerd wilt hebben door zoekmachines:
- enkel canonieke URL toe
- alleen URL’s met statuscode 200 retourneren
- dus geen redirects of 404 pagina’s
- Maak een sitemap niet te groot:
- Zorg ervoor dat een sitemap-bestand niet groter is dan 50 MB of 50.000 URL’s.
- Het is meestal interessanter om meerdere subsitemaps aan te maken.
- We zien dat kleinere sub-sitemappen van 1.000 URLs gemakkelijker kunnen worden ingelezen door de bots.
- Als je meerdere sitemaps gebruikt, maak dan een index-sitemap die ze allemaal vermeldt.
- Zorg ervoor dat je sitemap is gecodeerd in UTF-8
- Werk je sitemap automatisch bij telkens er een nieuwe URL bijkomt of verdwijnt;
- Voeg een verwijzing naar je sitemap toe in je robots.txt-bestand;
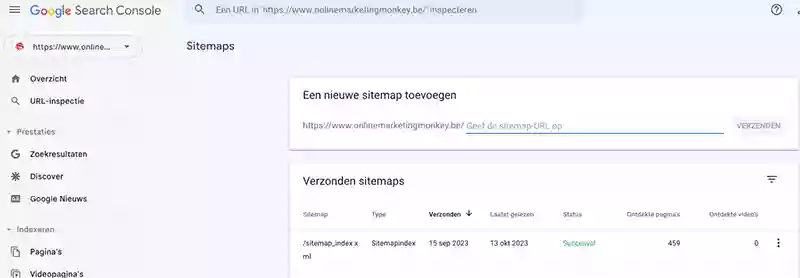
- Dien je sitemap in bij Google via je Search Console account en controleer de status ervan regelmatig.
Ook nog goed om weten
Suggereren is niet gelijk aan indexeren
Eerst en vooral, een XML-sitemap zal er niet automatisch voor zorgen dat jouw pagina’s geïndexeerd worden. Een sitemap-seo is een hulpmiddel voor zoekbots die jouw website crawlen. Deze zullen de pagina’s op jouw websites enkel effectief indexeren indien ze volgens hen kwalitatief genoeg zijn om dat te doen.
Wanneer je dus een XML-sitemap toevoegt aan je Google Search Console account, doe je dus niets minder, maar zeker ook niets meer dan een suggestie aan Google over de pagina’s die het volgens jou waard zijn om geïndexeerd te worden.
Wees consequent
Zorg voor een heldere en vooral eenduidige boodschap richting de crawlers die het web crawlen. Wanneer je aan de ene kant een bepaalde pagina opneemt in het robots.txt-bestand om te verhinderen dat deze geïndexeerd wordt en aan de andere kant die URL ervan wel opneemt in de XML-sitemap, zaai je verwarring. Idem wanneer je voor bepaalde pagina’s meta robots instelt met “noindex, follow” om te verhinderen dat Google deze pagina’s na het crawlen ook indexeert, maar diezelfde pagina’s vervolgens wel doodleuk opneemt in de sitemap.
Interessante vragen over XML-sitemaps
Een html user sitemap is een aanklikbaar html overzicht van alle URL’s die aanwezig zijn op een website. Het is bedoeld om “menselijke” websitebezoekers een algemeen overzicht van de alle site-pagina’s te bezorgen. Een XML sitemap daarentegen is bestemd om zoekmachines een algemeen beeld van de URLs op de site te geven.
Er zijn een aantal goede sitemap tools op de markt aanwezig, zoals deze van Screaming Frog en XML-Sitemap.com. Daarnaast bevatten de meeste CMS-en (Content Management Systemen) plugins om de XML aan te maken. Zo is Yoast waarschijnlijk wel de bekendste plugin voor WordPress.
Voor kleinere websites (< 1000 URLs) met beperkt development budget is het geen absolute must. Google is heden ten dage meestal slim genoeg ook zonder de sitemap haar weg te vinden op een kleinere site. Voor grote websites zijn ze volgens Google wel een minimum SEO vereiste.
Je SEO & XML sitemappen eens grondig laten analyseren? Neem dan gerust eens vrijblijvend contact met ons op!