
Hier bij Online Marketing Monkey vinden we het belangrijk om onze SEO kennis steeds verder te verbeteren. Zo kende ik persoonlijk het vrij onbekende Crawlstatistieken rapport in Google Search Console niet zo goed. Ik ben daar eens grondig ingedoken en het is voor SEO professionals echt wel interessant.
Wat is het Crawlstatistieken rapport eigenlijk?
Het crawlstatistieken rapport in Google Search Console is een technische SEO tool. Het laat SEOers en webmasters toe te onderzoeken hoe Google jouw website crawlt. Je gebruikt het dus om de werking van Googlebot beter te begrijpen.
Het crawlstatistieken rapport omvat volgende statistieken:
- Totaal aantal crawlverzoeken
- Totale dowloadgrootte
- Gemiddelde reactiesnelheid
- Algemene beschikbaarheid hosting
- De crawlverzoeken per responstype
- Crawlverzoeken per bestandstype
- Aantal crawlverzoeken per doel
- Crawlverzoeken per googlebot-type
Je kan Google natuurlijk niet verplichten dagelijks je hele website te crawlen. Maar wat je wel in eigen handen hebt, is het begrijpen waarom er soms vreemde fluctuaties in de crawlstatistieken van je site optreden.En die kan je dus ontdekken met het crawlstatistieken rapport.
Voorbeeld
Plotselinge dalingen of pieken in het rapport zijn vaak indicaties dat er iets fout gaat op een website:
- Constateer je bijvoorbeeld een significante daling in het totale aantal crawlverzoeken, dan zou het best eens kunnen dat de robots.txt van je website (ongevraagd?) is gewijzigd;
- Of je ontdekt dat je site langzaam reageert op Googlebot. Dat kan een teken zijn dat de webserver niet alle verzoeken de baas kan.
Dit wil je natuurlijk onderzoeken en oplossen.
Waar vind je het Crawlstatistieken rapport?
Het rapport zit goed weggestopt in Google Search Console :-). Je kan het vinden in je GSC-account onder Instellingen > Crawlen > Crawlstatistieken > Rapport Openen
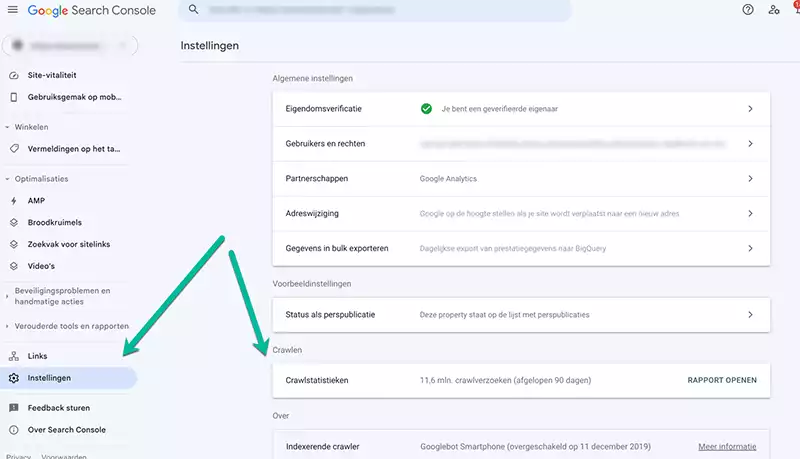
In onderstaande video legt Daniel Waisberg, search advocate bij Google, een algemene uitleg uit over het crawlstatistieken rapport.
Wat is crawlen ook al weer ?
Maar misschien eerst nog een stapje terug.
Wat is crawling eigenlijk?
Crawling is het ontdekkingsproces waarbij de zoekmachines bots, ook wel spiders of crawlers genoemd, het web opsturen om nieuwe en vernieuwde URLs te vinden. Die worden dan vervolgens toegevoegd aan hun index.
Het type content waarnaar gezocht wordt door die crawlers kan variëren: een webpagina, een afbeelding, een video, een PDF ect. Ze worden ontdekt via hyperlinks of sitemaps.
Crawlbudget (het aantal pagina’s van een website die Googlebot kan en wil crawlen) is essentieel voor SEO, zeker voor grote websites. Als je problemen hebt met het crawlbudget, is het perfect mogelijk dat Google sommige van je waardevolle pagina’s niet indexeert. En wat Google niet indexeert, bestaat online niet.
Het verband tussen en SEO en crawling, indexering en ranking wordt in onderstaande infographic nog eens uitgelegd:

SEO opportuniteiten opsporen in Crawlstatistieken rapport
Om het crawl-budget voor jouw website te optimaliseren, moet je eerst weten aan welke pagina’s het wordt besteed. Het Crawl Statistieken-rapport biedt een schat aan informatie over het crawlproces door Googlebot. We bespreken hieronder de belangrijkste secties die regelmatig technische SEO opportuniteiten van een website blootleggen.
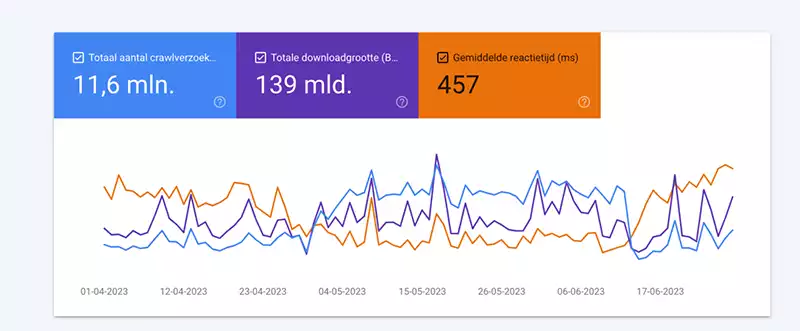
Totaal aantal crawlverzoeken
- Omvat het totale aantal crawlverzoeken dat een domein ontving van Googlebot in de afgelopen 90 dagen.
- Het totaal aantal crawlverzoeken slaat niet op het aantal gecrawlde pagina’s; immers, het aantal verzoeken is onderverdeeld naar bestandstype (zie verder); in het voorbeeld zien we 11,6M aanvragen, waarvan er 26% html-bestanden zijn; we kunnen dus veronderstellen dat ongeveer 3,0M URL’s de afgelopen 90 dagen zijn gecrawld.
- Erg praktisch om te analyseren of het aantal crawlverzoeken correleert met het aantal pagina’s dat je wil laten crawlen.
- Een plotselinge toename kan erop wijzen dat nieuwe URLs worden geïndexeerd, terwijl een afname kan duiden op technische problemen.
Totale download grootte
- De totale grootte van alle bestanden (html, afbeeldingen, CSS, scripts) in bytes die tijdens het crawlen door Googlebot zijn gedownload. Misschien is de totale download-grootte representatiever voor het crawlbudget dan het totale aantal crawlverzoeken. Immers, Google kan bijvoorbeeld veel 404-error-URLs tegenkomen, waarvoor het veel minder bytes moet downloaden in vergelijking met 200-URLs (daar moeten de pagina nog gerenderd worden).
- Indien je zowel deze statistiek als crawlverzoeken selecteert, dan zie je dat deze 2 meestal vrij nauw samen lopen. Als je bijvoorbeeld de bestandsgrootte van afbeeldingen zou verminderen, zou dat normaal een verandering in de downloadgrootte teweeg brengen
Gemiddelde reactiesnelheid
- Wat ons betreft de belangrijkste statistiek.
- De gemiddelde pagina-reactietijd is de tijd voor een crawlverzoek om de pagina content op te halen.
- Het geeft een beeld of je hosting snel en consistent is, of hoe het reageert tijdens drukke dagen; een hogere tijd kan duiden op server- of hostingproblemen.
- Het geeft weer hoe snel een website URLs aan Googlebot kan tonen.
- De reactietijd van de server dient best redelijk snel te zijn, omdat websites die traag reageren ook veel minder snel worden gecrawld.
- Er is een omgekeerde correlatie tussen responstijd en crawlverzoeken:
- als de responstijd hoger is (dus bij een trage website), wordt het aantal crawlverzoeken lager. Dat komt omdat crawlbudget een op tijd gebaseerd concept is. Googlebot zal maar een bepaalde tijd op een website aanwezig zijn.
- hoe langer het duurt voordat een site reageert, hoe minder pagina’s bijgevolg zullen gecrawld worden.
- Deze tijd is exclusief de tijd voor het ophalen van paginabronnen zoals scripts of rendering.
- Dus om website-crawling te optimaliseren, verbeter je best de gemiddelde reactietijd. Alleen, server-responstijden zijn afhankelijk van veel verschillende factoren, die allemaal technisch van aard zijn en waarvan er veel niet eenvoudig te verbeteren zijn, zoals hosting, caching- en CDN-instellingen.
- Een goede responstijd is een punt van discussie. Idealiter is die minder dan 200 ms, maar dat is voor de meeste websites niet realistisch. Ons inziens is een gemiddelde responstijd van 600 ms of sneller acceptabel. Langzamer wordt best aangepakt en verbeterd.
- Ter indicatie. In het Crux dashboard voor de Core Web Vitals hanteert Google een TTFB (time to first byte) van 800 ms als drempelwaarde: er onder is OK & erboven ‘needs improvement’.
Status van de host
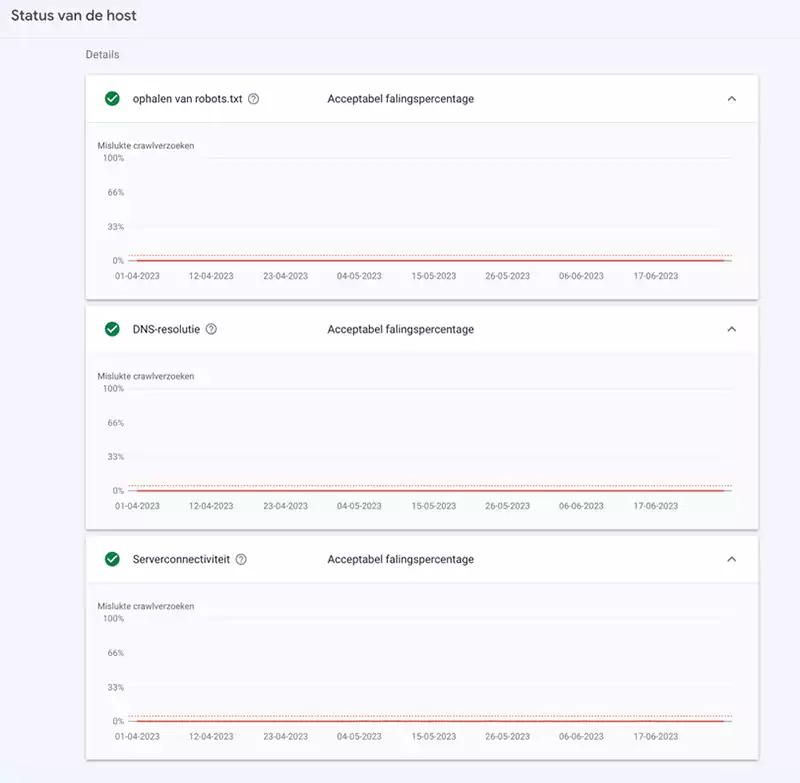
Het dashboard van het Crawlstatistieken rapport verstrekt veder informatie over:
- of de robots.txt file tijdens iedere crawl kon opgehaald worden;
- DNS-foutpercentages worden beschouwd als een probleem als ze een benchmarkwaarde voor die dag overschrijden;
- Serverconnectiviteit: Foutpercentages worden beschouwd als een probleem als ze een benchmarkwaarde voor die dag overschrijden.
Crawl-respons-codes
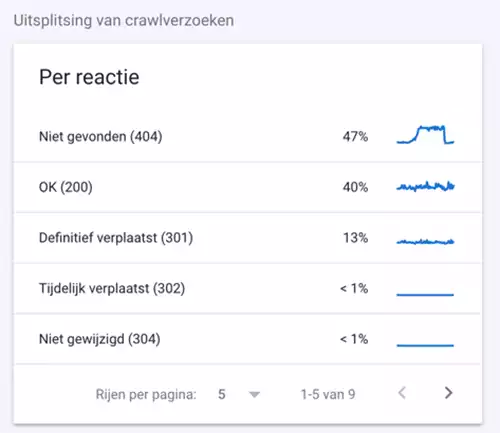
- Crawlreacties geven de website-respons weer die Googlebot ontvangt op haar crawlverzoeken.
- Het eerste wat een site doet wanneer het gecrawld wordt, is reageren met een HTTP-statuscode. Deze statuscode vertelt webbrowsers wat voor soort antwoord het ontvangt.
- Ze zijn gegroepeerd op code (zoals 200, 30X, 40X en 5xx) en tonen hoeveel procent van het crawlbudget ervoor is gebruikt.
- Het grootste deel van de codes is best 200 = OK. Het is belangrijk om hier te weten welk percentage van het crawlbudget is gebruikt voor niet-200 reacties en om navenant bij te sturen.
- Met de metriek voor geretourneerde statuscodes kun je bepalen welk percentage van je crawlbudget wordt gebruikt voor redirects (301), niet gevonden pagina’s (404) en server-errors(50X).
- Zie bovenstaand voorbeeld waarbij ‘Niet gevonden (404)’ maar liefst 47%. Als je dit soort statistieken ziet, raad ik je aan om verder onderzoek te doen. Immers je wil weten waarom het aantal 40X pagina’s zo plotseling zijn gestegen.
Crawlverzoeken per bestandstype
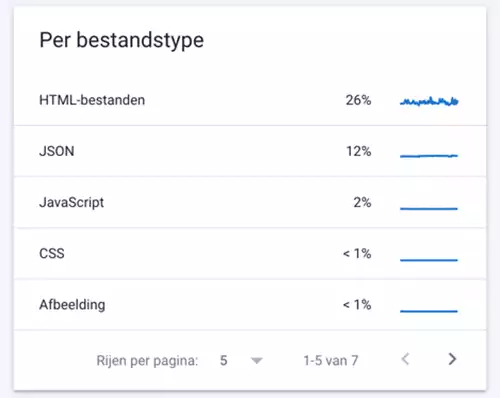
- Toont de percentages van het crawlbudget die gebruikt worden voor de diverse file types zoals HTML, JSON, Javascript, CSS, afbeeldingen, video en audio.
- Inzicht in hoe vaak Google specifieke typen bronnen zoals Javascript en CSS opvraagt, kan een rol spelen in bijvoorbeeld het type rendering dat je inzetten.
- Als de vindbaarheid van afbeeldingen belangrijk is voor jouw site, toont dit rapport hoe goed Googlebot die afbeeldingen kan crawlen.
- Zeker grote nieuwswebsites willen uiteraard het liefst dat hun artikelen worden gecrawld; dus ze willen een zo hoog mogelijk percentage aan html hebben.
- Als er veel crawlinspanningen worden besteed aan andere bestandstypen, kan dit betekenen dat Google minder crawlbudget beschikbaar heeft pagina’s te crawlen.
Crawls per doel
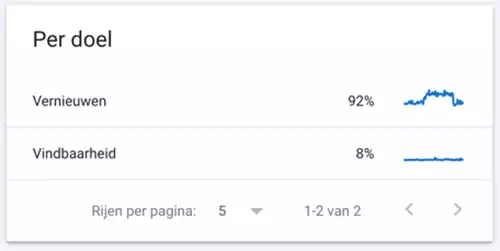
- Het crawldoel geeft aan of Google een URL opvraagt die het nog niet eerder heeft tegengekomen of dat het gaat om een bekende pagina met vernieuwde content:
- Als je onlangs veel nieuwe URLs hebt toegevoegd aan de website, zie je waarschijnlijk een toename in crawls voor “Vindbaarheid” = URLs die dus voor de eerste keer gecrawld werden. Dus als je onlangs veel nieuwe content hebt gepubliceerd, kan je hier controleren of het is opgepikt door de crawlers.
- Als je pagina’s hebt met vaak veranderende inhoud, zul je waarschijnlijk grotere percentages “Vernieuwen” crawls zien = recrawls van al bekende URLs die Google opnieuw bezocht.
- Dergelijke crawls per doel ga je beter te begrijpen door de voorbeeld-URLs te bekijken; zo krijg je een beter zicht op welke pagina’s prioriteit krijgen.
- Als SEO zou ik verwachten dat “Vernieuwen” voor de meeste sites ongeveer 80% of meer van Google’s crawling vertegenwoordigt, en Vindbaarheid zo’n 20% of wat minder.
- Voor de meeste online uitgevers en nieuws-website zoals HLN of De Tijd is een “Vindbaarheid” van meer dan 10% een reden tot bezorgdheid. Het betekent namelijk dat Googlebot veel nieuwe URL’s ontdekt om te crawlen. Dit kan wijzen op een crawlverliesprobleem met URL’s die Googlebot mogelijk onnodig crawlt, zoals duplicate content.
- Eventuele verbonden acties kunnen onder meer zijn:
- oplossen problemen XML sitemap
- fout in robots.txt-bestand rechtzetten
- verbeteren interne linking
- optimalisering crawl budget (bijvoorbeeld als het gemiddeld aantal dagelijks gecrawlde URLs veel kleiner is dan de totale website; zo kwamen we onlangs een site tegen waar het meer dan een jaar zou duren vooraleer de volledige site gecrawld zo zijn … )
Crawls per googlebot type in Crawlstatistieken rapport
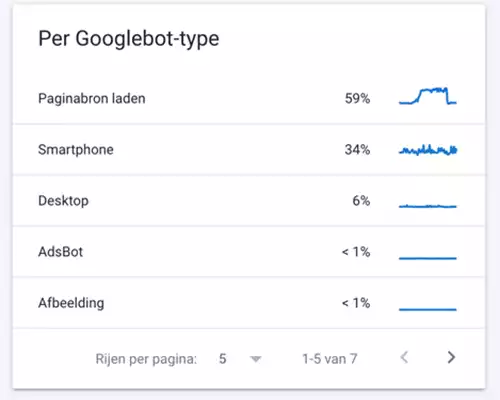
- Hier zie je de crawls naar Googlebot Type: smartphone, desktop, afbeeldingen, ads, video, etc – uw site bezoeken en hoe vaak ze dat doen.
- Aangezien Google een mobiel-first benadering heeft voor het crawlen en indexeren, zou Smartphone het type met de hoogste percentages dienen te zijn. Google checkt eveneens de desktopcontent van websites (opdat deze niet afwijkt van de mobiele) waardoor Desktop ook mestaal een redelijk % kent.
- Een probleem dat vaak voorkomt is dat er veel crawl-inspanning verloren gaan aan ‘Paginabron laden’. Dat betekent dat Googlebot veel tijd besteedt aan het crawlen van pagina-elementen die geen HTML zijn. Zoals bijvoorbeeld JavaScript-files, CSS-bestanden en lettertypebestanden, elementen die noodzakelijk zijn om een webpagina visueel te tonen aan gebruikers.
- Om de tijd die Google besteedt aan deze paginabronnen te verminderen: tracht lichtere URLs zonder overbodige extra informatie aan te bieden. Deze pagina’s laden dan sneller en verbeteren het crawlbudget.
Belang crawlstatistieken rapport voor SEO
Search bots crawlen (lees: doorzoeken) het internet en plaatsen nieuwe en bijgewerkte URLs in enorme databases. Die worden vervolgens gecontroleerd op alle gevonden woorden en meta-informatie, samen met de locatie van elke pagina. Zodra een surfer een zoekwoord intypt in een browser, wordt die mega-index doorzocht op de meest relevante resultaten, die dan in een fractie van een seconde in de zoekresultaten weergegeven worden.
Indien echter een website verhindert dat search engines haar webpagina’s kunnen crawlen of indexeren, dan kan die site niet ranken in de zoekresultaten. En dat is natuurlijk niet zo goed voor SEO.
Nu, wat heeft dit te maken met het crawlstatistieken rapport ?
Wel, tijdens dit indexerings-proces zullen bots niet alle URLs gaan crawlen. Dit is des te meer van belang voor grote websites zoals nieuwssites. Dergelijke sites hebben er alle baat bij dat de belangrijkste nieuwspagina’s wel degelijk maximaal gecrawld en geïndexeerd worden. Is dat niet het geval, wel, dan kunnen ze er ook niet voor ranken.
Het Google Search Console Crawl Stats-rapport is dus een grote hulp voor technische SEO. Het verstrekt bruikbare data om te debuggen van problemen bij website-prestaties. Het rapport maakt het eveneens eenvoudig om hostingproblemen, bronnen die te veel crawlbudget opslokken of 404-fouten te diagnosticeren.
Verschil met Log file analyse ?
- Het grootste verschil met SEO log file analyse is dat het rapport enkel Google-bot-activiteiten weergeeft. Maar er zijn uiteraard nog andere zoekmachines, zoals Bing, Yahoo, Yandex, …
- Een groot voordeel van de crawlstats is dat niet steeds zware logfiles bij je webmaster hoeft op te vragen; zeker als je werkt voor grote firma’s heb je die meestal niet meteen beschikbaar;
- Met het crawlstats rapport kan je nu het doel van elk Google-bezoek aan een website bepalen, wat niet mogelijk is met logfile analyses;
- Een nadeel is dat je slechts steeds 1 voorbeeld van de gecrawlde URL’s kan consulteren, je krijgt niet de volledige lijst te zien;
- Het filteren op datums is een ander manco, net als het feit dat de data tot een week kunnen achterlopen.;
- SEO Logfile analyse blijft dus nog steeds belangrijk. Beschouw het Google Crawlstats-rapport eerder als een aanvulling op SEO Logfile analyse.
Pro SEO Tip
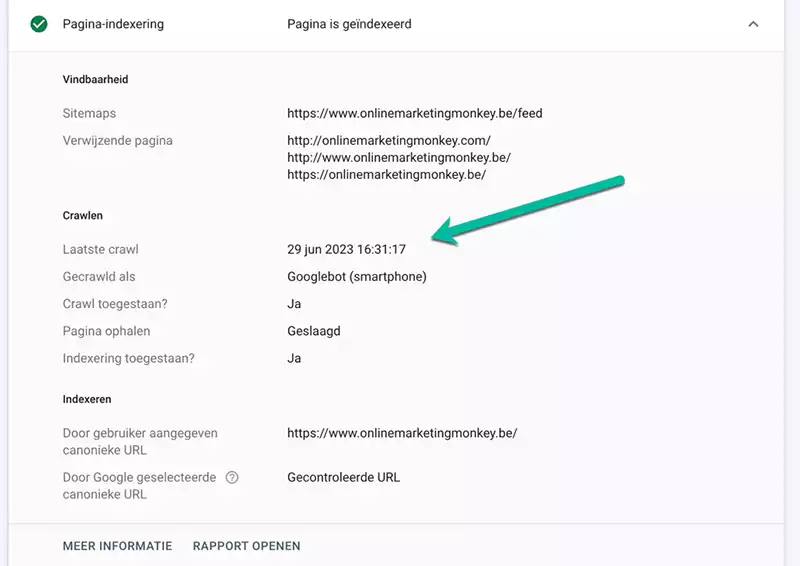
Je kan de link leggen tussen het crawlstatistieken rapport en de URL inspectie tool. Als je vermoedt dat bepaalde belangrijke URLs niet frequent genoeg gecrawld worden, kan je dat door de inspectie tool laten checken. Als de laatste crawl alweer enkele maanden oud is, dan verbeter je best je de interne en externe linking van de URLs in kwestie.
Meer bijleren over SEO? Schrijf je dan in op onze maandelijkse nieuwsbrief!



